Have you ever notice a degradation in the performance of your AI models?
Developing an AI model involves, in medical imaging as in any other field, a comprehensive process with several critical steps. It begins with data gathering and preparation, ensuring the data is clean, relevant, and suitable for analysis. Next, the design phase involves creating the initial model architecture and selecting appropriate algorithms. Multiple experiments and validations are conducted to test various configurations and approaches. These experiments help to refine the model, optimize its parameters, and improve its accuracy and performance. This iterative process continues until the best-performing AI model is identified. This model is then selected for integration into a final solution, ready to be deployed and utilized for practical applications.
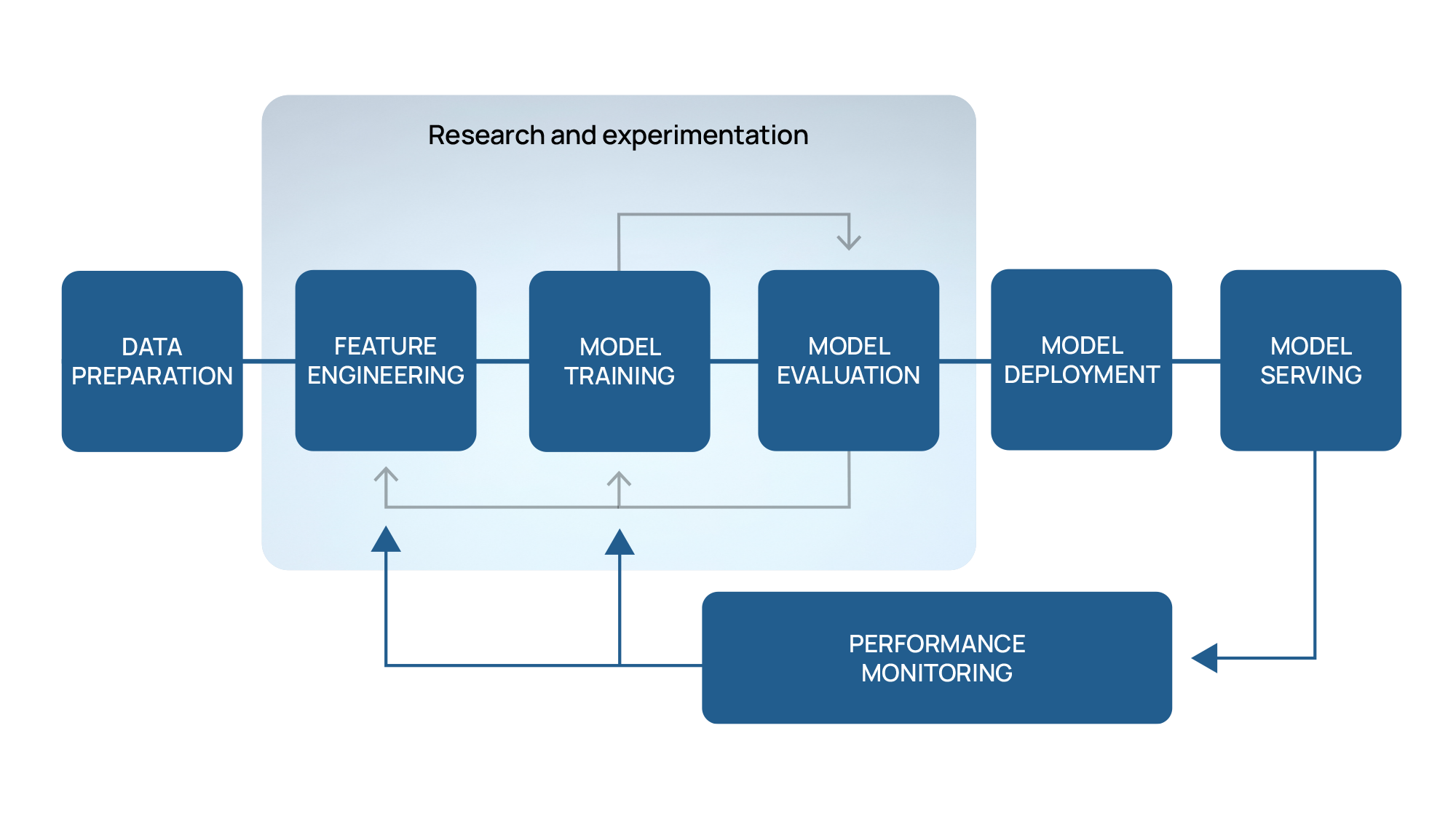
Figure 1 – AI model development workflow
However, the AI workflow should not conclude once the model is deployed in production. Over time, the models in production will suffer a decay in their predictive power, a phenomenon known as Model Drift. This decline results from continuous changes in the data used as input for the models. Examples of these changes in the medical imaging field can arise from new developments in imaging technologies or alterations in acquisition protocols. Consequently, the models encounter data they need to be trained on, leading to a potential decrease in the accuracy of their medical predictions.
Therefore, it is crucial to continuously monitor the AI models’ performance to identify such issues and develop strategies to mitigate them. Model drift can be broadly categorized into two main types:
Concept Drift
Concept drift occurs when the patterns learned by the model from the training/testing data change, leading to new, unseen patterns in the production data. For instance, in the field of medical imaging, this can happen with the emergence of new diseases or treatments. At the onset of the COVID19 pandemic, AI models initially trained to identify anomalies in chest X-rays were not able to detect COVID19 related anomalies. This is a clear example of concept drift.
Covariate or Data Drift
This type of drift happens when the distribution of features in the training/test data differs from that in the prediction data. Covariate drift can be further divided into input drift and output drift.
Input Drift
This involves changes in the input data, such as alterations in medical images or features caused by modifications in scanners. This may affect AI models, as models trained on images from current scanners might not perform well with images from future scanners, if new imaging reconstruction or novel contrast techniques are used.
Output Drift
This occurs when there are shifts in the distribution of the model’s output, which can result from changes in reporting guidelines.
An example of this issue could be a medical imaging model trained to classify the stages of primary tumors in lung cancer. Suppose the model was developed using data classified according to the 7th Edition of the TNM Staging of Lung Cancer. If new data in production adheres to the 8th Edition guidelines, the model’s output distribution will shift. This change can lead to decreased performance, as the model may no longer align with the updated standards, potentially resulting in inaccuracies in staging the primary tumor.
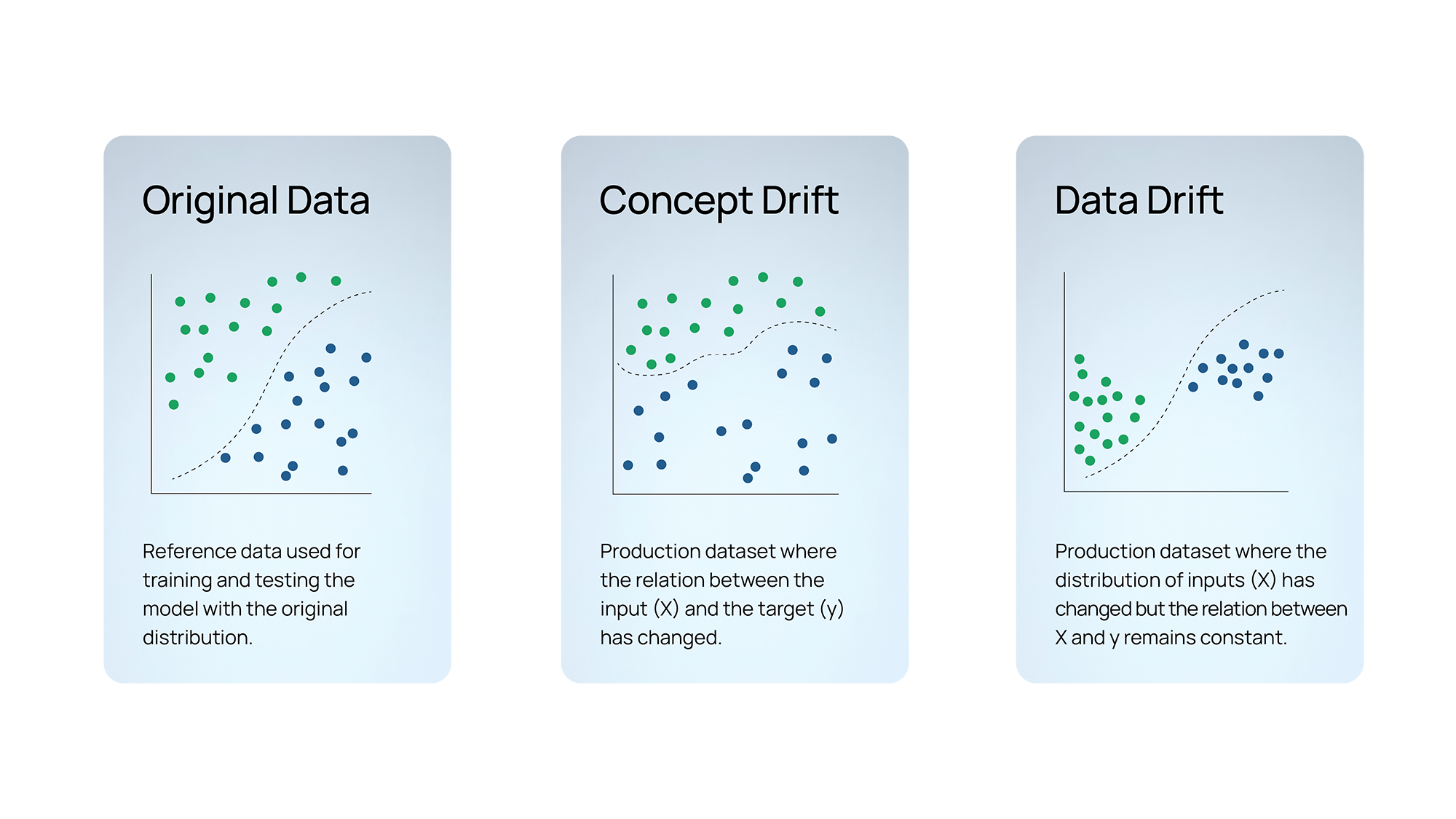
Figure 2 – Concept and data drift
Detecting the model drift
There are two main strategies to detect model drift, depending on the availability of ground truth (actual values):
Supervised drift detection
When ground truth becomes available sometime after the model’s predictions, it can be used to compare against these predictions using the same validation strategies employed during model development and selection. If the metrics obtained in production are significantly worse than those from the validation phase, the model is experiencing drift.
Unsupervised drift detection
A more challenging approach is required in scenarios where ground truth is unavailable. We will focus here on this scenario, which is the most common in real-world applications.
Several methods for detecting drift in an unsupervised manner vary based on the type of data, algorithm, and whether they utilize input or output predictions.
- Statistical –tests-based approaches
One of the most widely employed methods involves statistical tests that compare data distributions. These tests operate under the hypothesis that if significant statistical disparities exist between the reference data (utilized for training and testing) and the analysis data (employed in production), we cannot assume the model will yield similar results across both datasets.
Typically, these tests compare numerical or categorical variables by computing certain metrics to gauge the divergence between the two datasets. If these differences surpass a specified threshold, the algorithm considers that drift is present. Some examples of these methods are the Two-sample Kolmogorov-Smirnov test, Chi-square test, Wassertein distance or Kullback-Leibler divergence.
- Classification-based approaches
Another approach involves AI algorithms to detect differences between datasets, specifically between reference and production datasets. One example is the Domain Classifier. In this method, a model is trained using a subset of both reference and production data. If the model can accurately determine whether new data points belong to the reference or production domain, it indicates significant differences between the datasets. This implies that the data in production is different from the reference dataset, potentially affecting the model’s predictive performance.
- Uncertainty-based approaches
Other methods leverage the model’s uncertainty in production to detect drift. Model uncertainty measures how confident the model is about its predictions and can be monitored during production. If the model begins to show higher uncertainty in its predictions, it could indicate that specific characteristics of the production data are reducing the model’s confidence. This may signal a potential decline in performance.
Performance monitoring in Quibim
In Quibim, we recognize the importance of monitoring our models’ performance in production and detecting decreases in predictive accuracy as early as possible. We are continually researching the best approaches for each of our models in production.
In our products, we integrate a monitoring system as a post-market surveillance strategy, in order to detect, as soon as possible, potential sources of drift and minimize them, improving the customer experience. Additionally, we are at the forefront of developing tools to monitor production models through European-funded projects like ProCAncer-I and RadioVal. In these projects we are developing tools that incorporate multiple methods for detecting drift in the AI models in production for different use cases.
We are employing statistical test-based methods to detect changes in the distribution of input data. Specifically, we are developing solutions to identify differences within the radiomics features extracted either at an organ or lesion level in different use cases.
In RadioVal, radiomics features are used to predict patients’ response to neoadjuvant chemotherapy. Similarly, in ProCAncer-I, predictive models based on radiomics features are being developed for the early diagnosis, treatment allocation and response prediction, and monitoring of prostate cancer patients. Based on the assumption that the distributions of these features should remain consistent between reference and production data, if inconsistencies are found, it may indicate that the model is making predictions on data different from what it was trained and validated on, which could affect its performance.
A complementary approach has been developed for targeting the input data drift. In this second scenario, we are focused directly on the imaging data. In ProCAncer-I we are utilizing approaches which involve employing Auto-Encoders, AI algorithms that can be used to extract deep features from images. These deep features, represented as numerical values, are used by AI models to perform tasks such as image reconstruction. However, they can also be used for comparing data distributions. If deep features from training and testing data are significantly different from those extracted from production data, it may be an indicative of model drift.
Finally, we are incorporating additional methods to detect target drift in our classification models. These methods compare the distribution of the model’s outputs between reference data and production data using also statistical tests. If significant changes are detected, further analysis of the data is necessary to exclude the possibility of a decrease in the model’s classification performance in production.
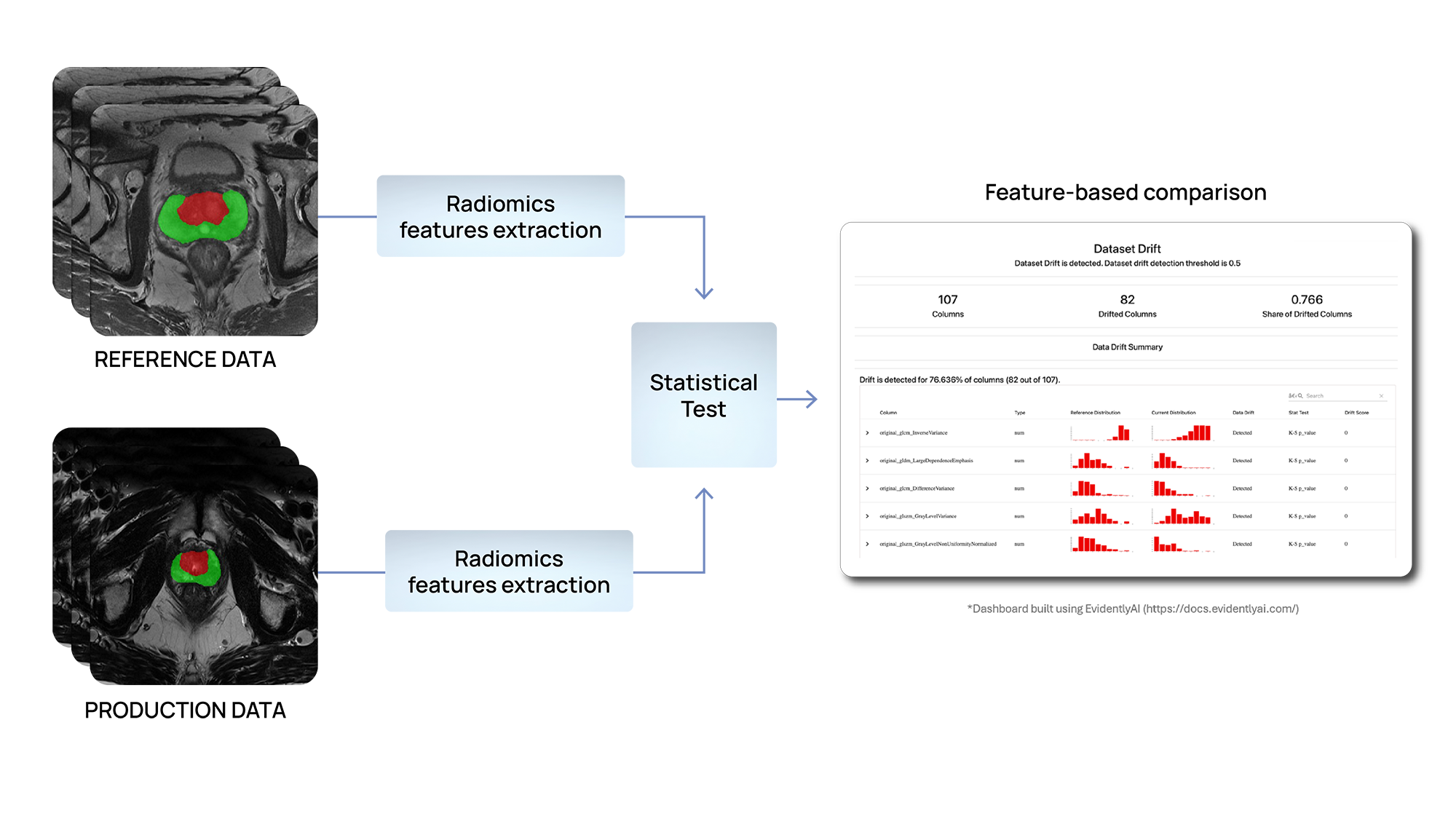
Figure 3 – Data drift detection using radiomics features