Haben Sie schon einmal beachten eine Verschlechterung der Leistung of Ihre KI-Modelle?
Die Entwicklung eines KI-Modells umfasst, in der medizinischen Bildgebung wie in jedem anderen Bereich, ein umfassender Prozess mit mehreren kritischen Schritten. Es beginnt mit Datenerfassung und -aufbereitung, um sicherzustellen, dass die Daten sauber, relevant und für die Analyse geeignet sind. Als nächstes umfasst die Entwurfsphase Erstellen der anfänglichen Modellarchitektur und Auswählen geeigneter Algorithmen. Es werden zahlreiche Experimente und Validierungen durchgeführt, um verschiedene Konfigurationen und Ansätze zu testen. Diese Experimente helfen, das Modell zu verfeinern, seine Parameter zu optimieren und seine Genauigkeit und Leistung zu verbessern. Dieser iterative Prozess wird fortgesetzt, bis die leistungsstärkste AI Modell wird identifiziert. Dieses Modell wird dann für die Integration in eine endgültige Lösung ausgewählt, die für die Bereitstellung und Nutzung in der Praxis bereit ist.
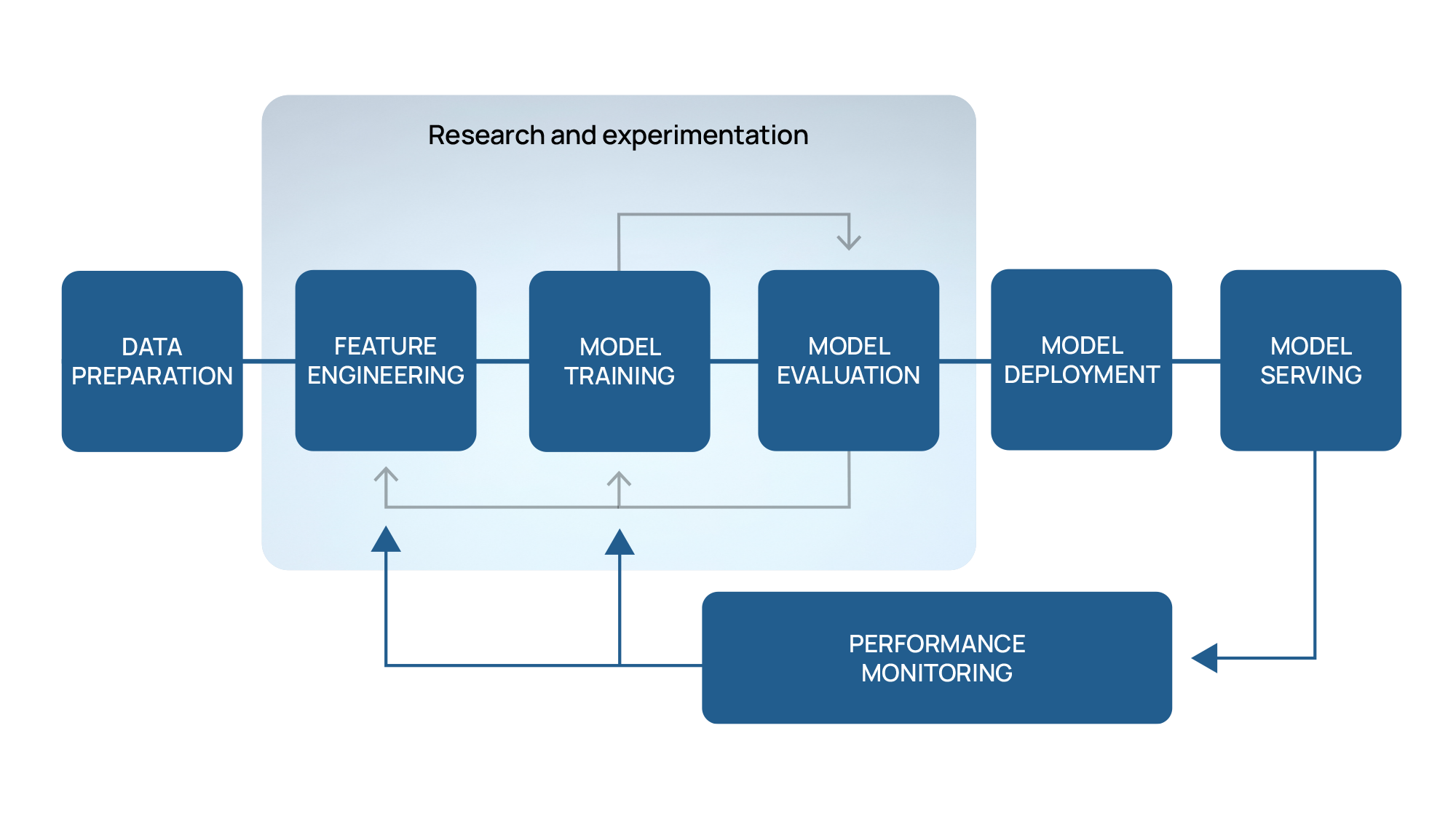
Abbildunge 1 - Workflow zur Entwicklung von KI-Modellen
Der KI-Workflow sollte jedoch nicht mit der Bereitstellung des Modells in der Produktion abgeschlossen sein. Im Laufe der Zeit Die Vorhersagekraft der Modelle in der Produktion nimmt ab; dieses Phänomen wird als Modelldrift bezeichnet. Dieser Rückgang ist auf kontinuierliche Änderungen der Daten zurückzuführen, die als Eingabe für die Modelle dienen. Beispiele für diese Änderungen im Bereich der medizinischen Bildgebung können sich aus neuen Entwicklungen in der Bildgebungstechnologie oder aus Änderungen in den Erfassungsprotokollen ergeben. Folglich stoßen die Modelle auf Daten, mit denen sie trainiert werden müssen, was zu einer potenziellen Verringerung der Genauigkeit ihrer medizinischen Vorhersagen führen kann.
Daher ist es wichtig, die Leistung der KI-Modelle kontinuierlich zu überwachen, um solche Probleme zu erkennen und Strategien zu ihrer Minderung zu entwickeln. Modelldrift kann grob in zwei Haupttypen eingeteilt werden:
Konzeptdrift
Konzeptdrift kommt vor wenn sich die vom Modell aus den Trainings-/Testdaten gelernten Muster ändern, Dies führt zu neuen, ungesehenen Mustern in den Produktionsdaten. Im Bereich der medizinischen Bildgebung kann dies beispielsweise bei der Entstehung neuer Krankheiten oder Behandlungen passieren. Zu Beginn der COVID19-Pandemie waren KI-Modelle, die ursprünglich darauf trainiert wurden, Anomalien in Röntgenaufnahmen der Brust zu erkennen, nicht in der Lage, COVID19-bezogene Anomalien zu erkennen. Dies ist ein klares Beispiel für Konzeptdrift.
Kovariate oder Datendrift
Diese Art von Drift tritt auf wenn die Verteilung der Merkmale in den Trainings-/Testdaten von der in den Vorhersagedaten abweicht. Der Kovariatendrift kann weiter in Eingangsdrift und Ausgangsdrift unterteilt werden.
Eingangsdrift
Dabei handelt es sich um Änderungen der Eingangsdaten, wie z.B. Änderungen in Medizin Bilder oder Funktionen, die durch Änderungen an Scannern verursacht wurden. Dies kann Auswirkungen auf KI-Modelle haben, da Modelle, die mit Bildern aktueller Scanner trainiert wurden, mit Bildern zukünftiger Scanner möglicherweise nicht die gleiche Leistung erbringen, wenn neue Bildrekonstruktions- oder Kontrasttechniken zum Einsatz kommen.
Ausgabedrift
Das kommt vor wenn es zu Verschiebungen in der Verteilung der Modellergebnisse kommt, die sich aus Änderungen der Berichtsrichtlinien ergeben können.
Ein Beispiel für dieses Problem könnte ein medizinisches Bildgebungsmodell sein, das darauf trainiert ist, die Stadien von Primärtumoren bei Lungenkrebs zu klassifizieren. Angenommen, das Modell wurde unter Verwendung von Daten entwickelt, die gemäß der 7. Ausgabe des TNM-Staging of Lung Cancer klassifiziert wurden. Wenn neue Daten in der Produktion den Richtlinien der 8. Ausgabe entsprechen, verschiebt sich die Ausgabeverteilung des Modells. Diese Änderung kann zu einer Leistungsminderung führen, da das Modell möglicherweise nicht mehr den aktualisierten Standards entspricht, was möglicherweise zu Ungenauigkeiten bei der Stadienbestimmung des Primärtumors führt.
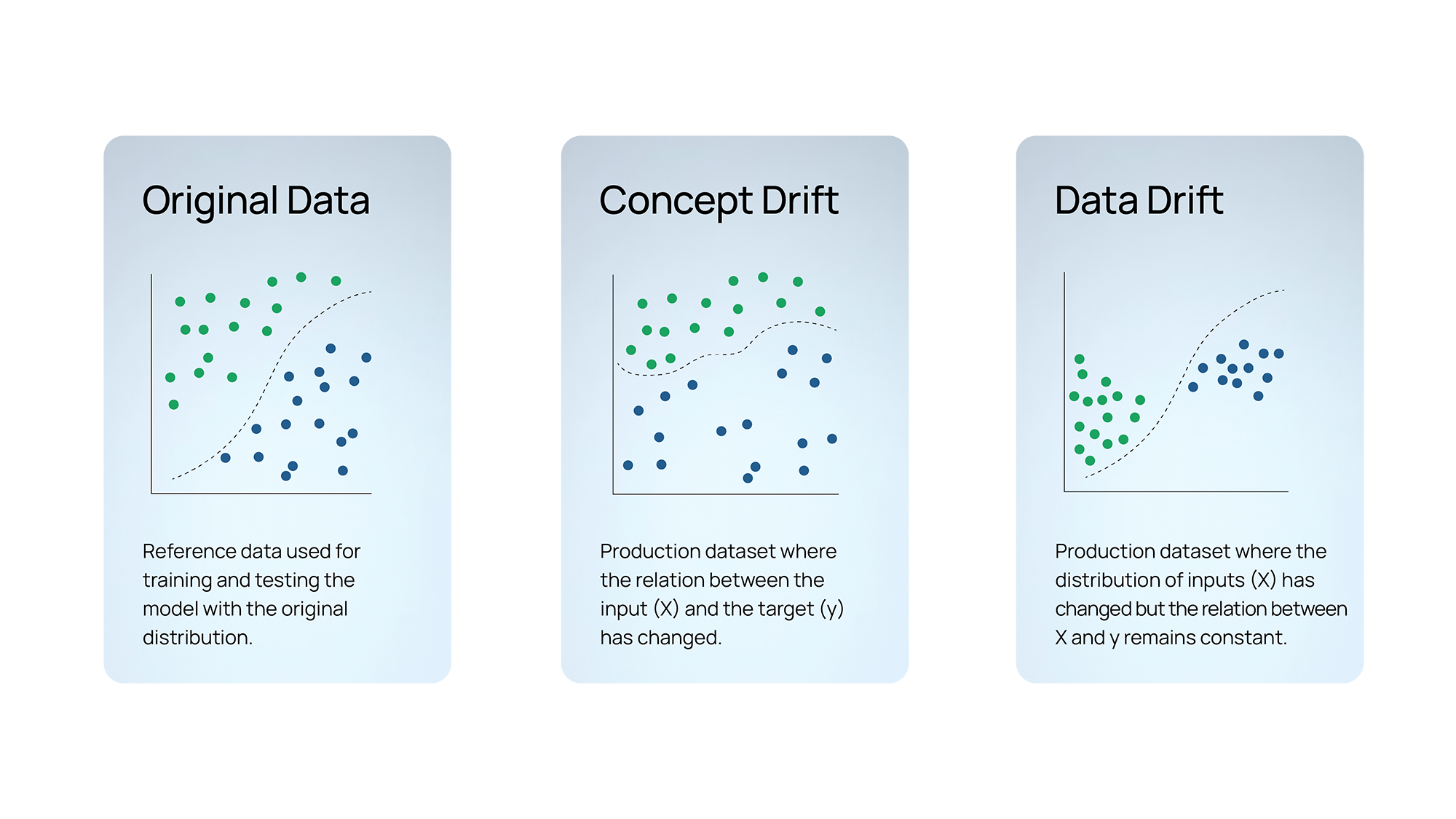
Abbildunge 2 - Konzept und Datendrift
Erkennen der Modelldrift
Es gibt zwei Hauptstrategien zur Erkennung von Modelldrift, abhängig von der Verfügbarkeit der Grundwahrheit (tatsächliche Werte):
Überwachte Drifterkennung
Wenn die Grundwahrheit irgendwann nach den Vorhersagen des Modells verfügbar wird, kann sie zum Vergleich mit diesen Vorhersagen verwendet werden unter Verwendung derselben Validierungsstrategien, die während der Modellentwicklung und -auswahl verwendet wurden. Wenn die in der Produktion erzielten Kennzahlen deutlich schlechter sind als die aus der Validierungsphase, weist das Modell eine Drift auf.
Unüberwachte Drifterkennung
In Szenarien, in denen keine Grundwahrheit verfügbar ist, ist ein anspruchsvollerer Ansatz erforderlichWir konzentrieren uns hier auf dieses Szenario, das in realen Anwendungen am häufigsten vorkommt.
Mehrere Methoden zur unbeaufsichtigten Drifterkennung variieren je nach Datentyp, Algorithmus und ob sie Eingabe- oder Ausgabevorhersagen verwenden.
- Statistische – testbasierte Ansätze
Eine der am häufigsten eingesetzten Methoden sind statistische Tests, die Datenverteilungen vergleichen. Diese Tests basieren auf der Hypothese, dass wir nicht davon ausgehen können, dass das Modell in beiden Datensätzen ähnliche Ergebnisse liefert, wenn zwischen den Referenzdaten (die für Training und Tests verwendet werden) und den Analysedaten (die in der Produktion eingesetzt werden) erhebliche statistische Unterschiede bestehen.
Normalerweise vergleichen diese Tests numerische oder kategorische Variablen, indem sie bestimmte Metriken berechnen, um die Abweichungen zwischen den beiden Datensätzen zu messen. Wenn diese Unterschiede einen bestimmten Schwellenwert überschreiten, geht der Algorithmus davon aus, dass eine Drift vorliegt. Einige Beispiele für diese Methoden sind die Kolmogorov-Smirnov-Test mit zwei Stichproben, Chi-Quadrat-Test, Wassertein-Entfernung or Kullback-Leibler-Divergenz.
- Klassifizierungsbasierte Ansätze
Ein anderer Ansatz umfasst KI-Algorithmen zum Erkennen von Unterschieden zwischen Datensätzen, insbesondere zwischen Referenz- und Produktionsdatensätzen. Ein Beispiel hierfür ist der Domain Classifier. Bei dieser Methode wird ein Modell mit einer Teilmenge von Referenz- und Produktionsdaten trainiert. Wenn das Modell genau bestimmen kann, ob neue Datenpunkte zur Referenz- oder Produktionsdomäne gehören, deutet dies auf signifikante Unterschiede zwischen den Datensätzen hin. Dies bedeutet, dass sich die Produktionsdaten vom Referenzdatensatz unterscheiden, was möglicherweise die Vorhersageleistung des Modells beeinträchtigt.
- Unsicherheitsbasierte Ansätze
Andere Methoden nutzen die Unsicherheit des Modells in der Produktion, um Abweichungen zu erkennen. Die Modellunsicherheit misst, wie sicher das Modell bei seinen Vorhersagen ist und kann während der Produktion überwacht werden. Wenn die Vorhersagen des Modells eine größere Unsicherheit aufweisen, könnte dies ein Hinweis darauf sein, dass bestimmte Merkmale der Produktionsdaten die Zuverlässigkeit des Modells mindern. Dies kann ein Hinweis auf einen möglichen Leistungsabfall sein.
Leistungsüberwachung in Quibim
In Quibimerkennen wir, wie wichtig es ist, die Leistung unserer Modelle in der Produktion zu überwachen und einen Rückgang der Vorhersagegenauigkeit so früh wie möglich zu erkennen. Wir erforschen kontinuierlich die besten Ansätze für jedes unserer Modelle in der Produktion.
In unsere Produkte integrieren wir ein Überwachungssystem als Strategie zur Überwachung nach der Markteinführung, um potenzielle Abweichungsquellen so schnell wie möglich zu erkennen und zu minimieren und so das Kundenerlebnis zu verbessern. Darüber hinaus Wir sind führend in der Entwicklung von Werkzeugen zur Überwachung von Produktionsmodellen durch Von der EU finanzierte Projekte Google Trends, Amazons Bestseller ProCAncer-I und RadioVal. In diesen Projekten entwickeln wir Tools, die mehrere Methoden zur Erkennung von Drift in den KI-Modellen in der Produktion für verschiedene Anwendungsfälle beinhalten.
Wir verwenden statistische testbasierte Methoden, um Änderungen in der Verteilung der Eingabedaten zu erkennen. Insbesondere entwickeln wir Lösungen, um Unterschiede innerhalb der Radiomics-Funktionen zu identifizieren, die in verschiedenen Anwendungsfällen entweder auf Organ- oder Läsionsebene extrahiert werden.
In RadioValwerden Radiomics-Merkmale verwendet, um die Reaktion der Patienten auf eine neoadjuvante Chemotherapie vorherzusagen. In ähnlicher Weise ProCAncer-I, Es werden prädiktive Modelle auf Basis von Radiomics-Merkmalen für die Frühdiagnose, Behandlungszuweisung und Reaktionsvorhersage sowie die Überwachung von Prostatakrebspatienten entwickelt. Basierend auf der Annahme, dass die Verteilungen dieser Merkmale zwischen Referenz- und Produktionsdaten konsistent bleiben sollten, Wenn Inkonsistenzen gefunden werden, kann dies darauf hinweisen, dass das Modell Vorhersagen auf der Grundlage anderer Daten trifft als jene, mit denen es trainiert und validiert wurde. Dies könnte seine Leistung beeinträchtigen.
Zur gezielten Bekämpfung der Drift der Eingabedaten wurde ein ergänzender Ansatz entwickelt. In diesem zweiten Szenario konzentrieren wir uns direkt auf die Bilddaten. In ProCAncer-I verwenden wir Ansätze, die den Einsatz von Auto-Encodern beinhalten, KI-Algorithmen, mit denen sich tiefe Merkmale aus Bildern extrahieren lassen.Diese als numerische Werte dargestellten Deep Features werden von KI-Modellen verwendet, um Aufgaben wie die Bildrekonstruktion auszuführen. Sie können jedoch auch zum Vergleichen von Datenverteilungen verwendet werden. Wenn sich Deep Features aus Trainings- und Testdaten erheblich von denen unterscheiden, die aus Produktionsdaten extrahiert wurden, kann dies ein Hinweis auf Modelldrift sein.
Schließlich haben Wir integrieren zusätzliche Methoden zur Erkennung von Zieldrift in unsere Klassifizierungsmodelle. Diese Methoden vergleichen die Verteilung der Modellergebnisse zwischen Referenzdaten und Produktionsdaten und verwenden dazu auch statistische Tests. Wenn signifikante Änderungen festgestellt werden, ist eine weitere Analyse der Daten erforderlich, um die Möglichkeit einer Verschlechterung der Klassifizierungsleistung des Modells in der Produktion auszuschließen.
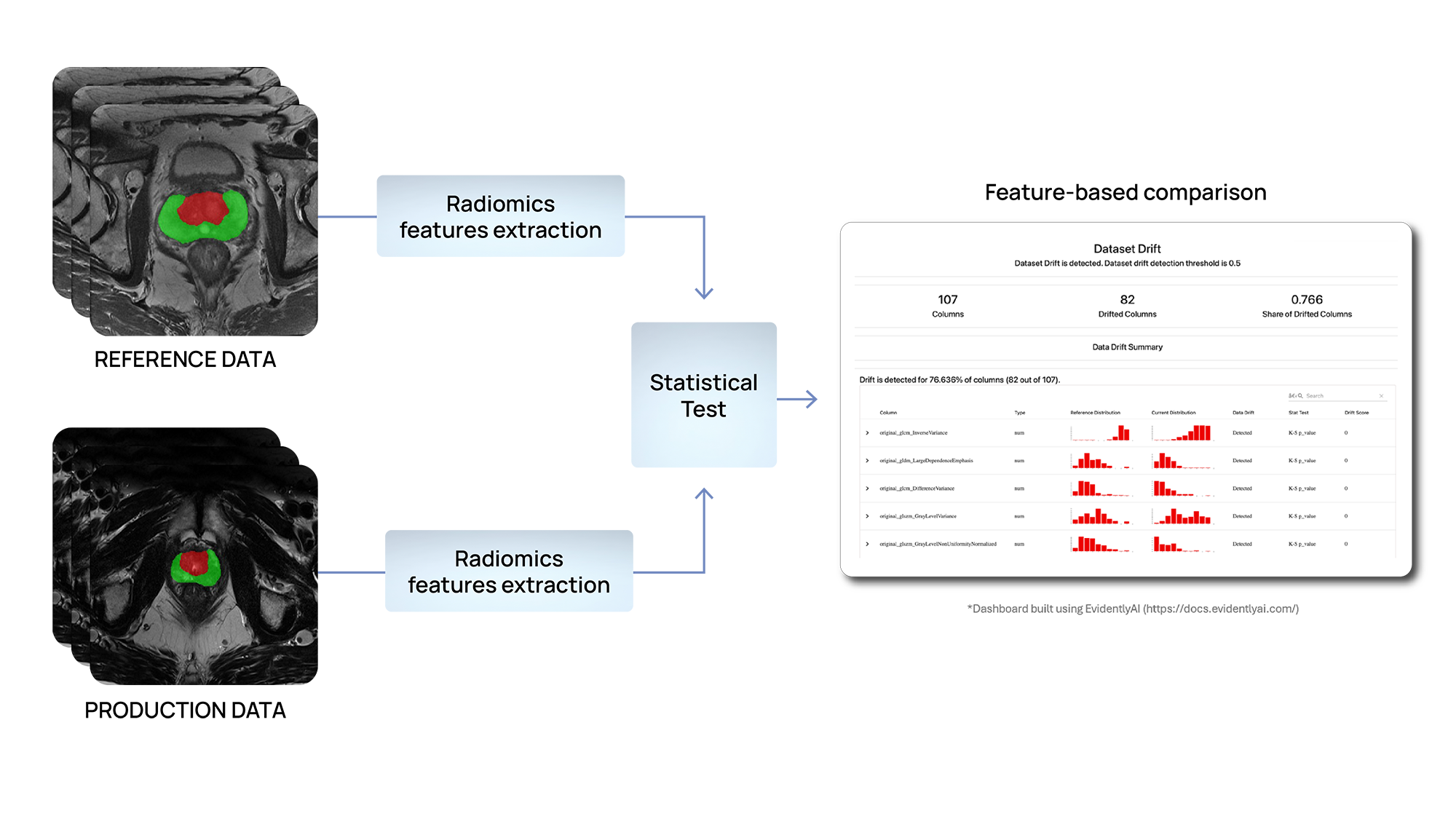
Abbildung 3 - Datendrifterkennung mithilfe von Radiomics-Funktionen